
直近3走×時系列モデルで“今”を評価する
今回は、レースIDを指定して出走各馬の直近傾向を数値化し、スタッキング構成の時系列モデルでスコアリング → Excelに一括転記するところまでを自動化しました。記事では処理の全体像と、学習時との違い、仕上げのExcel転記だけをシンプルに紹介します。
全体の流れ
- レースを指定して、そのレースの出走表・馬/騎手/調教師などの基本情報を取得
- 自前の過去データベース(
horse_db.csvや血統表)と縦に結合 - 直近3走にフォーカスした前処理・特徴量化
- 学習時と同一のエンコード&スケーリングを適用
- LSTM+SetTransformer+MoE+アテンションのハイブリッドで各馬スコアを算出
- 馬名・騎手名などと合体して見やすいテーブル化
- 仕上げにExcel(既存ブックの「レース」シート)へ一括貼り付け
予想の考え方(モデルの“目線”)
- 直近に重心:各馬の履歴から**直近3走(
sequence_length=3)**を切り出し、- 体重変化・距離/斤量の“その馬の平均からのズレ”
- クラス(距離カテゴリ×芝/ダ)に対する相対性
- 騎手成績や騎手×馬のコンビ相性
- 走破速度・上りのその馬×同条件での過去平均
- **血統の得意傾向(距離・脚質・馬場・芝ダ)**の累積指標
を時系列ベクトル化して評価します。
- 似た履歴の“なぞり”:直近シーケンスが過去のどの時点と似ているかをコサイン類似度で数値化(安全策込み)。「今の状態」が“良かった頃”に近いかどうかを一緒に見ます。
- モデル構成:
- LSTMで時系列の文脈を抽出 → Temporal Attentionで重要区間に重みづけ
- **Mixture-of-Experts(MoE)**で複数の見方を合成
- SetTransformerでレース内の“相対比較”を学習
- 最後はスタッキングで2系統の出力を統合し、各馬のスコアに落とします。
学習時との“違い”はここ!
“再学習”はせず、学習時の処理をそのまま当てるのがポイント。違いと注意点をまとめます。
- 同一のラベルエンコード
- 学習時に保存した
label_encoders.pklをそのまま適用。 - 未知カテゴリは -1 にフォールバック(学習時と同ルール)。
- 学習時に保存した
- 同一のスケーリング
scale_stats.jsonの mean/std と採用カラム順を再利用。- 分母0対策やNaN/Infのサニタイズも同じ。
- 同一の埋め込み次元
embedding_info.jsonの 入力/出力次元を厳密一致させてから重み読込。category_maps.jsonを使い、IDを学習時の埋め込みID空間にマッピング。
- 学習時と“同じ列順”でモデルに渡す
main_feature_order.jsonに保存した特徴量の順番を再現。- 足りない列は 0 で補完(学習と互換を崩さない)。
- 履歴の扱い
- 対象レースの該当馬のみに履歴をフィルタ。
- シーケンス不足は末行パディングで長さ3に統一(学習時と同様の扱い)。
出力と順位づけ
最終的に、各馬を1行にまとめた見やすいテーブルを作ります。
- 作る列(例)
- 枠番 / 馬番 / 馬名 / 性齢 / 斤量 / 馬体重 / 体重増減 / 騎手名
- 単勝 / 人気 / スコア順位(大きいスコア=上位)/ 過去履歴数
- スコアは降順でランキング。同点は最小順位(1,1,3…)で採番。
- ブログでは、上位数頭について**「なぜ上がったか」**を簡潔に言語化(例:
- 直近の体重推移が“良かった頃”に近い
- 同距離帯×芝/ダでの過去速度が相対的に高い
- 騎手の直近勝率やコンビ相性が良い
- 血統的に距離適性が積み上がっている …など)
Excel への一括転記
既存のExcelブック(「Iwasshoi8v1」)の**「レース」シート**に、9行目から横並びで書き込みます。列対応は以下の通り。
| Excel列 | データ列 |
|---|---|
| A列 | 枠番 |
| B列 | 馬番 |
| C列 | 馬名 |
| D列 | 性齢 |
| E列 | 斤量 |
| F列 | 馬体重 |
| G列 | 体重増減 |
| H列 | 騎手名 |
| I列 | 単勝 |
| J列 | 人気 |
| K列 | スコア順位 |
| L列 | 過去履歴数 |
- ブック名に 「Iwasshoi8v1」 を含むファイルが開かれている前提(見つからなければ明示エラー)。
- シート名は 「レース」 固定。
- 画面更新/自動計算を一時的にOFFにして高速化 → 最後に元へ戻す。
start_row = 9
n = len(df_out)
if n == 0:
raise RuntimeError("書き込む行がありません(df_out が空)")
excel = win32.Dispatch("Excel.Application")
target_book = None
for wb in excel.Workbooks:
if "Iwasshoi8v1" in wb.Name:
target_book = wb
break
if target_book is None:
raise RuntimeError("❌ ブック『Iwasshoi8v1』が開かれていません。Excelで開いてから実行してください。")
try:
ws = target_book.Worksheets("レース")
except:
raise RuntimeError("❌ シート『レース』がブックに存在しません。確認してください。")
# 画面更新/再計算オフで少し高速化
prev_calc = excel.Calculation
excel.ScreenUpdating = False
excel.EnableEvents = False
excel.Calculation = -4135
try:
for i, row in df_out.iterrows():
r = start_row + i
ws.Cells(r, 1).Value = "" if pd.isna(row["枠番"]) else row["枠番"]
ws.Cells(r, 2).Value = "" if pd.isna(row["馬番"]) else row["馬番"]
ws.Cells(r, 3).Value = "" if pd.isna(row["馬名"]) else str(row["馬名"])
ws.Cells(r, 4).Value = "" if pd.isna(row["性齢"]) else str(row["性齢"])
ws.Cells(r, 5).Value = "" if pd.isna(row["斤量"]) else float(row["斤量"])
ws.Cells(r, 6).Value = "" if pd.isna(row["馬体重"]) else float(row["馬体重"])
ws.Cells(r, 7).Value = "" if pd.isna(row["体重増減"]) else float(row["体重増減"])
ws.Cells(r, 8).Value = "" if pd.isna(row["騎手名"]) else str(row["騎手名"])
ws.Cells(r, 9).Value = "" if pd.isna(row["単勝"]) else float(row["単勝"])
ws.Cells(r,10).Value = "" if pd.isna(row["人気"]) else float(row["人気"])
ws.Cells(r,11).Value = "" if pd.isna(row["スコア順位"]) else int(row["スコア順位"])
ws.Cells(r,12).Value = int(row["過去履歴数"])
rb = ws.Range(f"A{start_row}:L{start_row}").Value
finally:
excel.Calculation = prev_calc
excel.EnableEvents = True
excel.ScreenUpdating = True
print("✅ 一括書き込み 完了")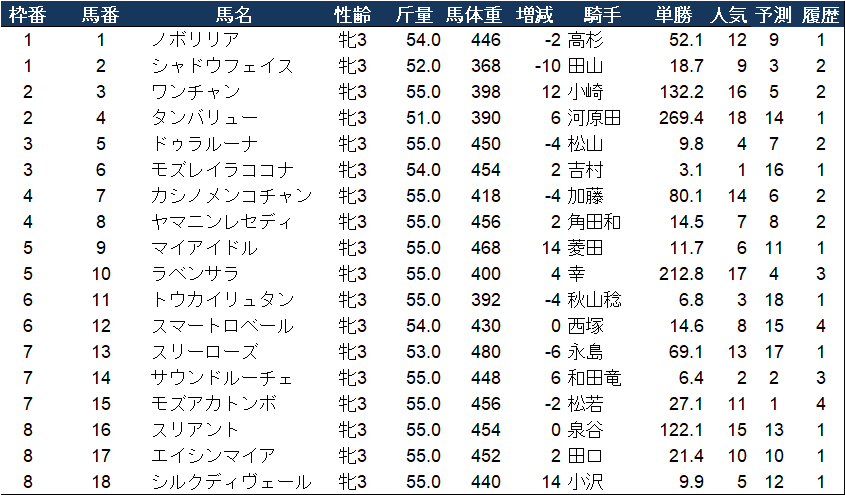
失敗時のチェックポイント
- ブックが開いているか/シート名が正しいか
df_outが空でないか(馬番の数がおかしくないか)- ラベルエンコード・スケール統計・埋め込み情報のファイル不整合がないか
- 対象レースの馬IDがきちんと取れているか(一致しないと
df_predsが空に)
使っている主な特徴量
- 距離/斤量の“自馬平均からの差分”(3,5,7走で移動平均&z-score)
- クラス基準(距離カテゴリ×芝ダ)の過去平均との差
- 馬体重の前走比/移動平均/z-score(推移のトレンド値)
- 騎手勝率(累積)と騎手×馬コンビ勝率
- 過去の走破速度・上りの自馬平均(同芝/ダ)
- **脚質のビン分け(逃げ・先行・差し・追込)**と直近履歴
- 血統キーからの得意カテゴリ(距離・脚質・馬場・芝ダ)の累積最多
まとめ
- 直近3走と相対指標で“今の出来”を定量化
- 学習時の前処理・エンコード・スケール・埋め込みを完全踏襲
- スコアはレース内相対で順位づけし、Excelへワンクリックで反映
- ブログはスコア上位馬の根拠を短く添えるだけで、説明力がアップします
次回、学習時をもとに推論する再のパッケージについて説明します。


コメント